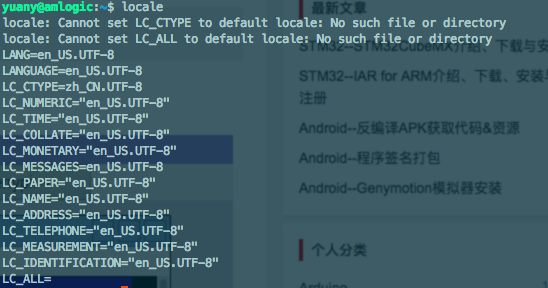
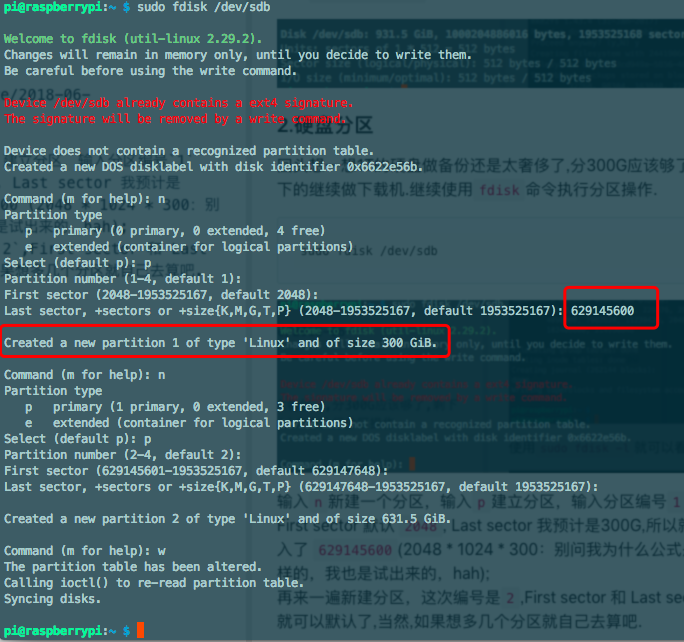
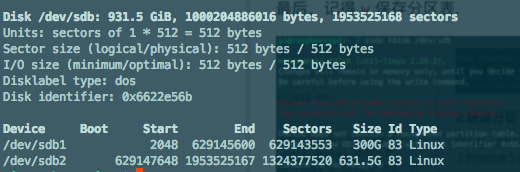
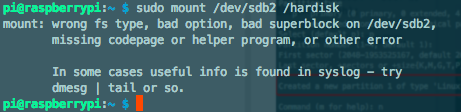
号码组成
中华人民共和国国家标准 GB 11643-1999《公民身份号码》中规定:公民身份号码是特征组合码,由十七位数字本体码和一位校验码组成。
公民身份号码是特征组合码,由十七位数字本体码和一位数字校验码组成。排列顺序从左至右依次为:六位数字地址码,八位数字出生日期码,三位数字顺序码和一位数字校验码。
-
地址码表示编码对象常住户口所在县(市、旗、区)的行政区划代码,按 GB/T 2260 的规定执行。
-
出生日期码表示编码对象出生的年、月、日,按 GB/T 7408 的规定执行。年、月、日代码之间不用分隔符。(例:某人出生日期为 1966 年 10 月 26 日,其出生日期码为 19661026。)
-
顺序码表示在同一地址码所标识的区域范围内,对同年、同月、同日出生的人编定的顺序号,顺序码的奇数分配给男性,偶数分配给女性。
-
校检码是根据前面十七位数字码,按照公式计算出来的检验码。
计算方法
-
将前面的身份证号码 17 位数分别乘以不同的系数,从第一位到第十七位的系数分别为:7 9 10 5 8 4 2 1 6 3 7 9 10 5 8 4 2 ;
-
将这 17 位数字和系数相乘的结果相加;
-
用加出来和除以 11,看余数是多少;
-
余数只可能有 0 1 2 3 4 5 6 7 8 9 10 这11个数字,其分别对应的最后一位身份证的号码为 1 0 X 9 8 7 6 5 4 3 2;
-
通过上面得知如果余数是 2,就会在身份证的第18位数字上出现罗马数字的 X。如果余数是 10,身份证的最后一位号码就是 2。
JavaScript代码实现:
function check(code) {
code = code.split('');
var factor = [7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2],
parity = [1, 0, 'X', 9, 8, 7, 6, 5, 4, 3, 2],
sum = 0,
ai = 0,
wi = 0;
for (var i = 0; i < 17; i++) {
ai = code[i];
wi = factor[i];
sum += ai * wi;
}
var last = parity[sum % 11];
return last == code[17];
}
问题:
这种方法只能做前端的简单校验,我们java后台进行的判断方式是根据省市县出身年月算出身份证后四位,比这种只对最后一位校验要精准得多,不过不是很清楚他们的做法